How to Speed up your Lakehouse Queries by an Order of Magnitude with Multi-modal Index Subsystem using Apache Hudi and Presto

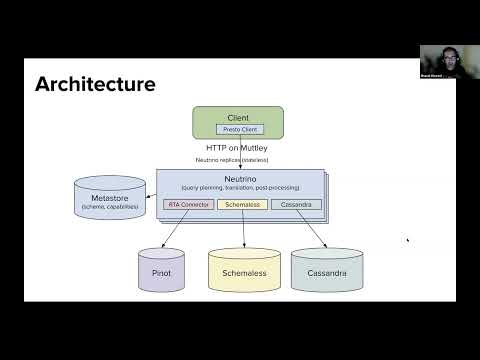
Sivabalan Narayanan of Onehouse shares more about how Apache Hudi brought transactions, incremental processing on top of data lakes, which are deemed as the foundational pillars for Lakehouse architecture. In this session, we will discuss Apache Hudi and how it fills the key technology gaps in the modern data architecture. Viewed from a data engineering lens, Hudi also plays a key unifying role between the batch and stream processing worlds realized by incremental processing model. We will take a look at the capabilities of native Hudi connector in Presto. We will dive deep into this connector, covering the key optimizations and features it unblocks. Presto users could now leverage the metadata table for optimized file listing and avoid large number of list operations in cloud storages. We will look at how we can improve the query latency in Presto using advanced data skipping methodogies employed with multi-modal sub-system with Hudi.