Apache Hudi for Presto and how it’s used at Bytedance
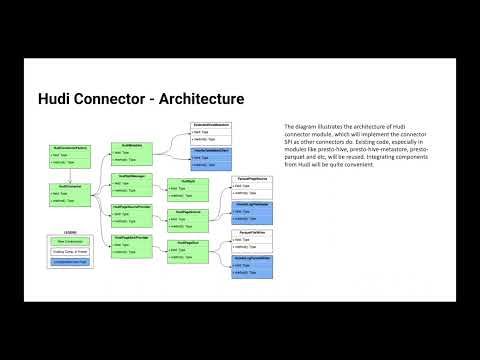
This month we’ll have Yanbing Zhang, software engineer at Bytedance, share more about their work on the Apache Hudi Connector for Presto and how they’re using it at Bytedance.
On-Demand Recordings from PrestoCon’s, Webinars, Meetups, and more
This month we’ll have Yanbing Zhang, software engineer at Bytedance, share more about their work on the Apache Hudi Connector for Presto and how they’re using it at Bytedance.

Varsity Tutors is a learning platform that enables online academic, professional, and enrichment learning. A growing part of their offering partners with school districts to provide customized support for teachers and students. Varsity Tutors for Schools provides external reporting capabilities including student assessments, progress reports, and more. To provide these timely reports, Varsity Tutors (an AWS shop) uses Presto scripts to perform federated queries across MySQL, Postgres, and Redshift and writes data back to S3. They use Ahana Cloud as their managed service for Presto. In this session, John will discuss what technologies they evaluated, why they chose Presto, and their current data architecture including how they handle security for cross-account writes and how they perform upserts into the final reporting database.

Biddut Sarker Bijoy will discuss his experience utilizing Presto in projects involving billions of data points. Many of the big data projects Biddut Sarker Bijoy worked on have had computational issues, such as the need to shrink datasets or the challenge of making sense of terabytes of data. Nonetheless, Biddut Sarker Bijoy recently worked on a project that required him to clean up a large database. Sometimes we all need to clean up a database. It was not a straightforward one for many reasons. Biddut Sarker Bijoy have found using Presto is the best-fitted one for this problem because of its architectural behavior and how it works with billions of data points within a very short amount of time as well as with a less amount of cost.

Over the last decade Presto has become one of the most widely adopted open source SQL query engines. In use at companies large and small, Presto’s performance, reliability, and efficiency at scale have become critical to many companies’ data infrastructures. In this panel we’ll hear from three of the largest companies running Presto at scale – Meta, Uber, and Intuit. They’ll share more about their learnings, some of their impressive performance metrics with Presto, and what they envision going forward for Presto at their respective companies.

Bolt.eu is the first European mobility super-app. We have over 100M users across Europe and Africa and have to deal with data at a large scale on a daily basis (over 100k queries daily). Previously we were using a traditional data warehouse solution based on Redshift but we’ve faced scalability issues that were hard to overcome and after doing our research we chose Presto as the solution. In just a single year we’ve managed to migrate to the Lakehouse architecture using AWS, Presto, Spark and Delta lake. We would like to talk about our journey, some of the challenges we’ve encountered and how we solved them.

Rajmani Arya, Varun Senthilnathan & Manoj Kumar Dhakad, Adobe Advertising: We are from the Product Engineering team in Adobe Advertising (https://business.adobe.com/in/product…. Adobe Advertising is a digital advertisement platform. We take care of accumulating all data, providing platform intelligence, building and maintaining machine leaning capabilities, building and maintaining internal pipelines that form derived data to be used by other teams. The volume of total incoming raw data ranges between 8 to 10 tb/ day spread across 7 regions. The total data in the system currently is about 7pb. This data is largely stored in Hive tables with a central metastore. We use Presto in three ways: 1. Data studio – an internal tool to enable data analysts, sales, marketing and other teams to do adhoc querying. This is also used by data engineers to do adhoc querying for engineering tasks. 2. Custom Reports – We create reports for customers to get performance insights on their campaigns. We have 100s of reports that are run on a daily basis. 3. Internal Pipelines – Presto is used to retrieve data to power 100s of pipelines run daily to generate derived data.

Twilio as a leader in cloud communication platforms is very heavy on data and data-based decision making. Most data related use cases are currently powered by the Presto engine. Two years back we started the Journey with Presto in Twilio and today the system has scaled to a multi-PB data lakehouse and supports more than 75k queries per day. In this journey, we learned a lot about how to effectively operationalize Presto on AWS and some of the tricks to have better query reliability, query performance, guard-railing the clusters and save cost. With this talk, we want to share this experience with the community.

Presto is used for a variety of cases, but tends to be used for larger scale analytical queries. We have been transitioning to using Presto to power our data platform and customer-facing scripting language, RQL (Rippling Query Language) to run arbitrary customer queries to power core products. Presto helps enable diverse, federated querying at scale. In this talk, Andy will cover where Presto sits in Rippling’s ecosystem as a core query layer, our collaboration and contributions for closer integration with Apache Pinot, and learnings on using Presto to handle a large variety of query patterns.

Presto has been widely used at Bytedance in several ways such as in the data warehouse, BI tools, ads etc. And, the Presto team at Bytedance has also delivered many key features and optimizations such as the Hive UDF wrapper, coordinator, runtime filter and so on which extend Presto usages and enhance Presto stabilities. Nowadays, most companies will use both Hive (or Spark) and Presto together. But Presto UDFs have very different syntax and internal mechanisms compared with Hive UDFs. This restricts Presto usage while users need to maintain 2 kinds of functions. In this talk, we will present a way to execute Hive UDF/UDAF inside Presto.

Amundsen is an open-source data discovery and metadata platform which is part of LF AI & Data foundation. In this talk, we will deep dive into Amundsen’s architecture and how we integrate Amundsen with Presto to power the data preview and data exploration.

In this talk we are going to introduce Presto cross environment query federation which will enable query execution across different clouds and on-prem Presto clusters. This helps in reducing the network data transfer which results in lower Egress and Ingress costs when we are querying across clouds.

Here, Chunxu and Beinan would like to share what they have learned in developing a highly-scalable query predictor service through applying machine learning algorithms to ~10 million historical Presto queries to classify queries based on their CPU times and peak memory bytes. At Twitter, this service is helping to improve the performance of Presto clusters and provide expected execution statistics on Business Intelligence dashboards.

In this talk, we present some of the work streams we have underway at Uber to optimize Presto performance. In particular, we will cover enabling aggregation pushdown in queries in order to use statistics in the file headers/footers, our investigations into and attempts to efficiently executing approximate queries, and our experience with humongous object allocation in Presto.

In this talk, WalmartLabs is sharing how they build Enterprise Distributed Query Service powered by Presto & Alluxio across clouds.

In this presentation, Dante and Fede will show Jampp’s data architecture, how they’re training their machine learning algorithms directly from Presto to identify potential purchasers, and why Presto has become 24/7 critical to ensure ads are relevant to users.

In this talk, Walaa describes how LinkedIn extended its Presto Hive Catalog with a smart logical abstraction layer that is capable of reasoning about logical views with UDFs by using two core components, Coral and Transport UDFs. Coral is a view virtualization library, powered by Apache Calcite, that represents views using their logical query plans. Walaa shows how LinkedIn leverages Coral abstractions to decouple view expression language from the execution engine, and hence execute non-Presto-SQL views inside Presto, and achieve on-the-fly query rewrite for data governance and query optimization.

