Getting started with the new Redis HBO for Presto (Aug 30, 2023)

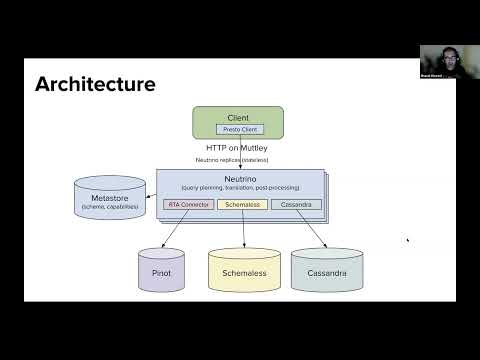
Learn more about the new open-source Redis-based Historical Statistics Provider for Presto from Jay Narale, software engineer at Uber who built it. Redis is an open-source in-memory database that integrates with Presto through a dedicated connector. Now with a Redis history-based optimizer, you can enhance the efficiency and speed of query execution for Presto by using historical stats to generate optimized plans for your queries. Jay will cover how the Redis HBO utilizes the in-memory capabilities of Redis to store & analyze historical query execution data, which helps the optimizer make informed decisions about query planning and resource allocation based on the historical patterns of queries, leading to improved execution times and resource utilization.