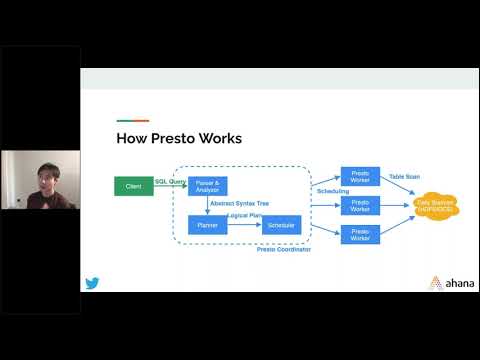
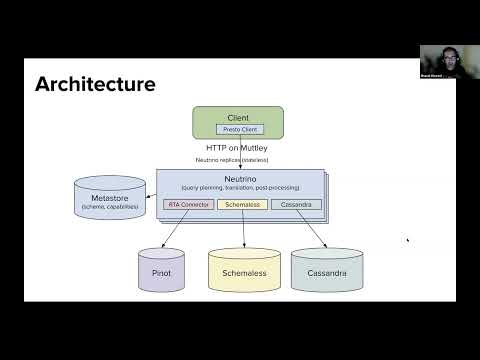
How Carbon uses PrestoDB in the Cloud with Ahana to Power its Real-time Customer Dashboards

Carbon is a real-time revenue management platform that consolidates revenue and audience analytics, data management, and yield operations into a single solution. Real-time analytics is super critical – their customers rely on real-time data to make revenue decisions. After facing issues around performance, visibility & ease of use, and serverless pricing model with AWS Athena, the team moved to a managed service for PrestoDB in the cloud – Ahana Cloud – to power their customer-facing dashboards. In this session, Jordan will discuss some of the reasons the team moved from AWS Athena to a managed PrestoDB on Intel-optimized AWS instances. He will also dive into their current architecture that includes an Ahana-managed Hive Metastore along with Apache ORC file format and an S3-based data lake. Last, he’ll share some performance benchmarks and talk about what’s next for PrestoDB at Carbon.