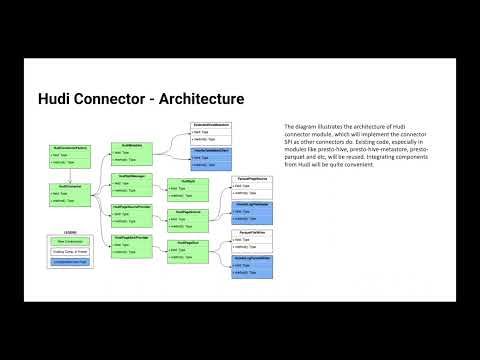
Varsity Tutors is a learning platform that enables online academic, professional, and enrichment learning. A growing part of their offering partners with school districts to provide customized support for teachers and students. Varsity Tutors for Schools provides external reporting capabilities including student assessments, progress reports, and more. To provide these timely reports, Varsity Tutors (an AWS shop) uses Presto scripts to perform federated queries across MySQL, Postgres, and Redshift and writes data back to S3. They use Ahana Cloud as their managed service for Presto. In this session, John will discuss what technologies they evaluated, why they chose Presto, and their current data architecture including how they handle security for cross-account writes and how they perform upserts into the final reporting database.