Solving Cross-Warehouse Joins for AI Systems Using Presto : Without Breaking Latency, Cost, or Correctness
This is a guest post from Apoorv, AI Lead Engineer at Sylus
The Distributed Intelligence Challenge
Problem Statement: “Show me last quarter’s ad spend next to the revenue it drove, by campaign.”
While this seems like a routine request for a human analyst, it creates a significant technical hurdle for AI systems when the required data is distributed across multiple platforms.
- Ad spend resides in specialized marketing warehouses.
- Revenue data is stored in transactional systems.
- Data must be joined on a common campaign_id.
- Results require cross-platform aggregation before being returned to the user.
The Challenge:
When we tasked our AI analyst with this query, the system struggled. The bottleneck wasn’t the analytical logic, but the inherent friction of data fragmentation. Moving large datasets between environments for a single join introduces latency and cost, often breaking the real-time experience users expect.
Legacy Constraints: Structural Failures
Prior to implementing federation, our architecture was restricted by a single-warehouse-per-session paradigm. This lack of interoperability manifested in three critical failure modes:
Failure Mode 1: Outright Refusal
Problem Statement: “I am unable to access both datasets simultaneously.”
The system simply hit a hard wall, declining the request due to siloed permissions.
Failure Mode 2: Manual ETL Workarounds
Attempting to consolidate fragmented data into a single environment proved inefficient:
- Prohibitive computational and storage costs.
- Significant latency in data movement.
- Stale results that failed to meet real-time requirements.
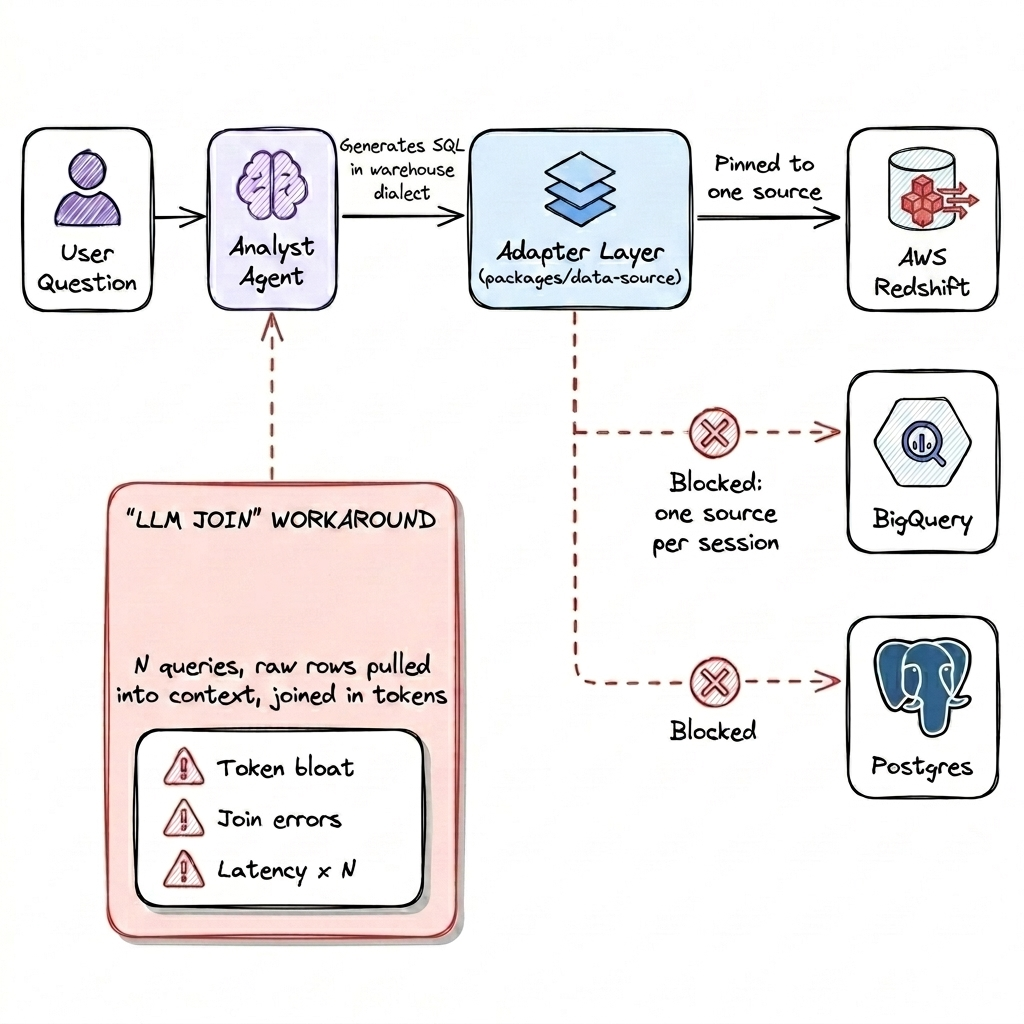
Failure Mode 3: The “LLM Join” Anti-Pattern
Tasking the model with orchestrating the logic internally led to consistent regressions:
- Executing decoupled queries across sources.
- Ingesting raw results into the model’s context window.
- Attempting non-deterministic joins in-memory.
This strategy collapsed under production pressure due to:
- Token saturation triggered by excessive intermediate data payloads.
- Analytical drift where joins lacked deterministic accuracy.
- Systemic latency from sequential API round trips.
The diagnostic conclusion was inescapable: An LLM context window is not a substitute for a high-performance query engine.
The Architectural Pivot: A New Mental Model
Our team initiated a fundamental reframing of the technical challenge: “The end-user is indifferent to the physical location of the data; they are optimizing for the accuracy and speed of the final result.”
This realization informed three core guiding principles for our federated strategy:
- Abstracting disparate sources into a unified logical system.
- Prioritizing compute-to-data proximity to minimize ingress/egress friction.
- Enforcing join execution external to the model’s context window.
The Solution: Federation Layer with Presto
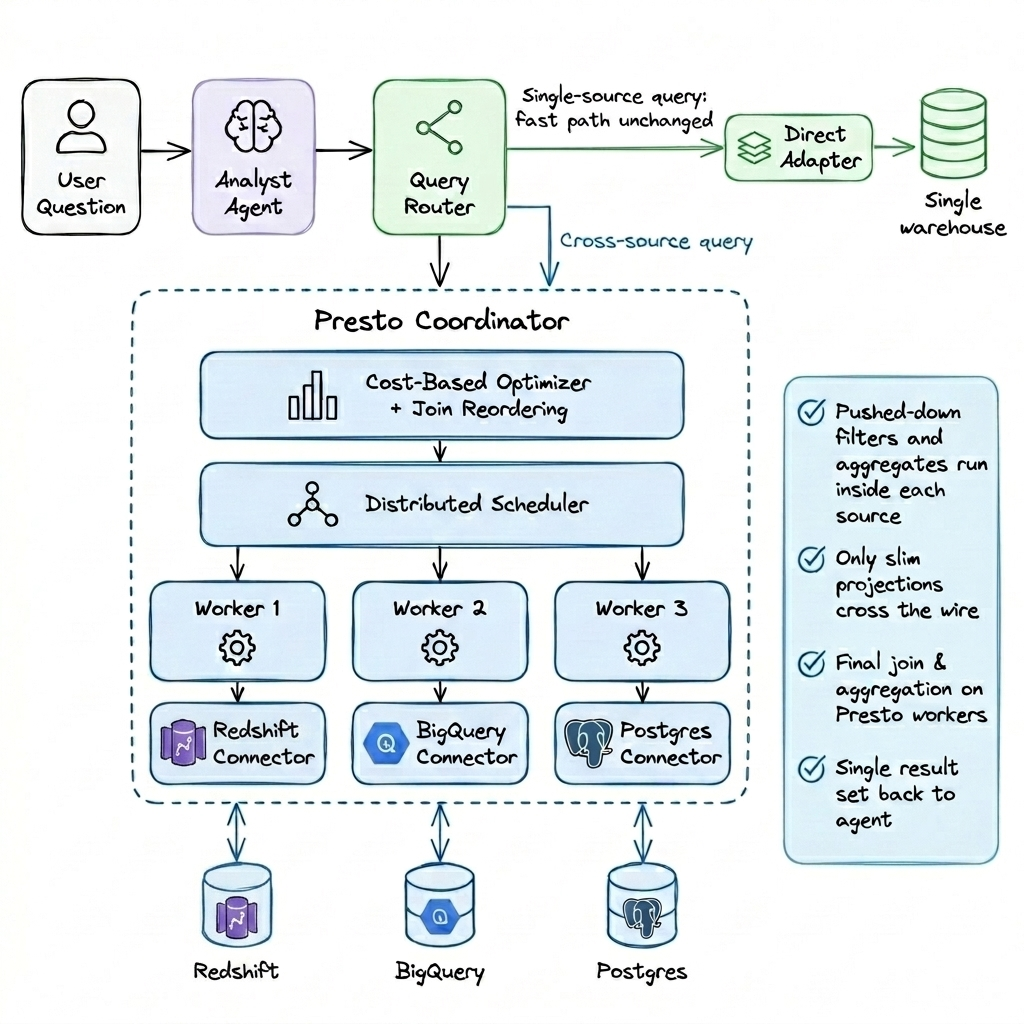
Our implementation involved the strategic integration of a federated query layer using Presto, positioned directly beneath the AI agent to streamline multi-source operations.
New Execution Flow
- The AI agent generates a single SQL query.
- A query router detects whether it spans multiple sources.
- Presto executes the query across systems.
- Only the final, compact result is returned.
The pivotal architectural shift: The agent no longer orchestrates joins; it delegates execution to the engine.
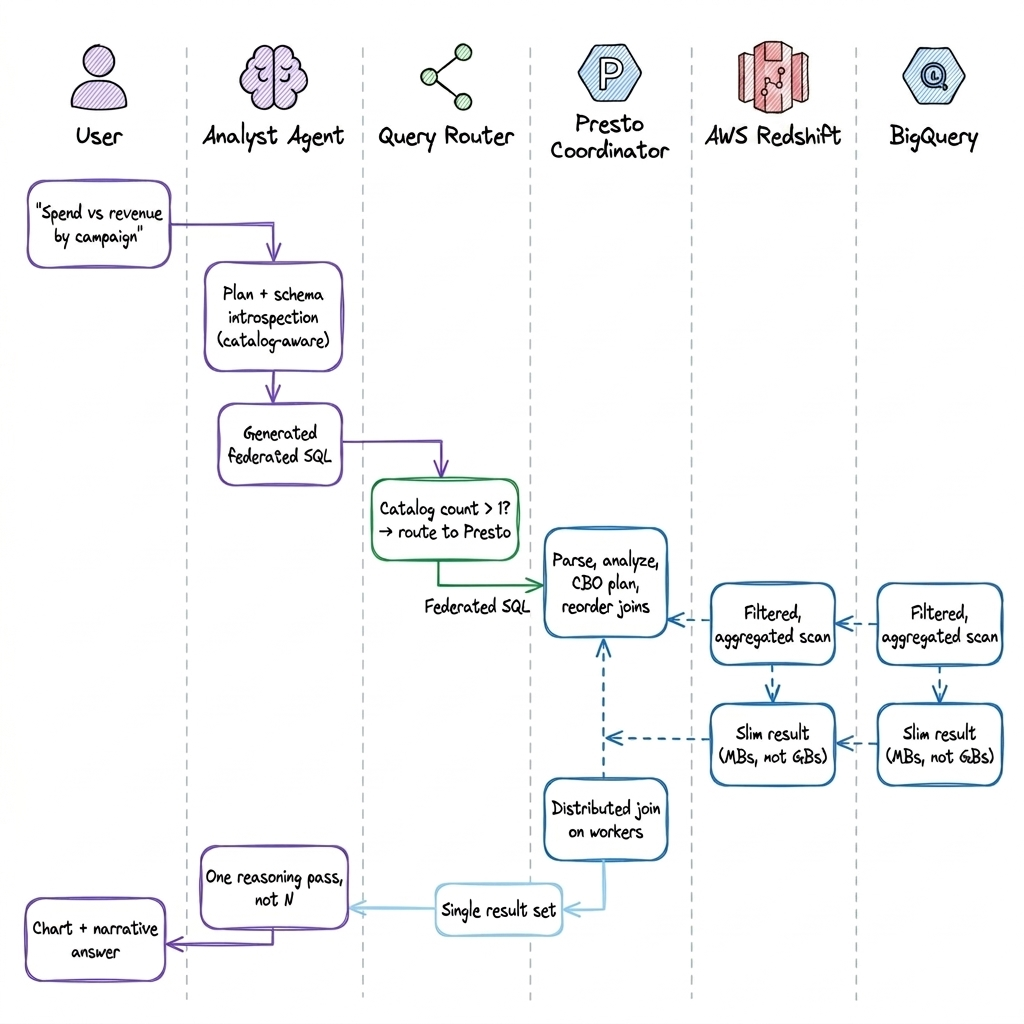
Systemic Evolution: The Operational Shift
This transition represents the most significant paradigm shift in our system’s behavioral architecture.
Old State: Distributed Orchestration
- Manual orchestration of execution logic across disparate systems.
- The model functioned as a bottleneck for consolidating cross-platform results.
- Fragmented reasoning requires multiple sequential cycles.
New State: Engine-Driven Efficiency
- Transition to a unified execution plan.
- Computation offloaded to the query engine for deterministic accuracy.
- Consolidation into a single, high-fidelity reasoning step.
The resulting architecture is fundamentally leaner and more performant.
Efficacy and Reliability: The Core Advantages
The robustness of this architectural approach is anchored by two fundamental properties:
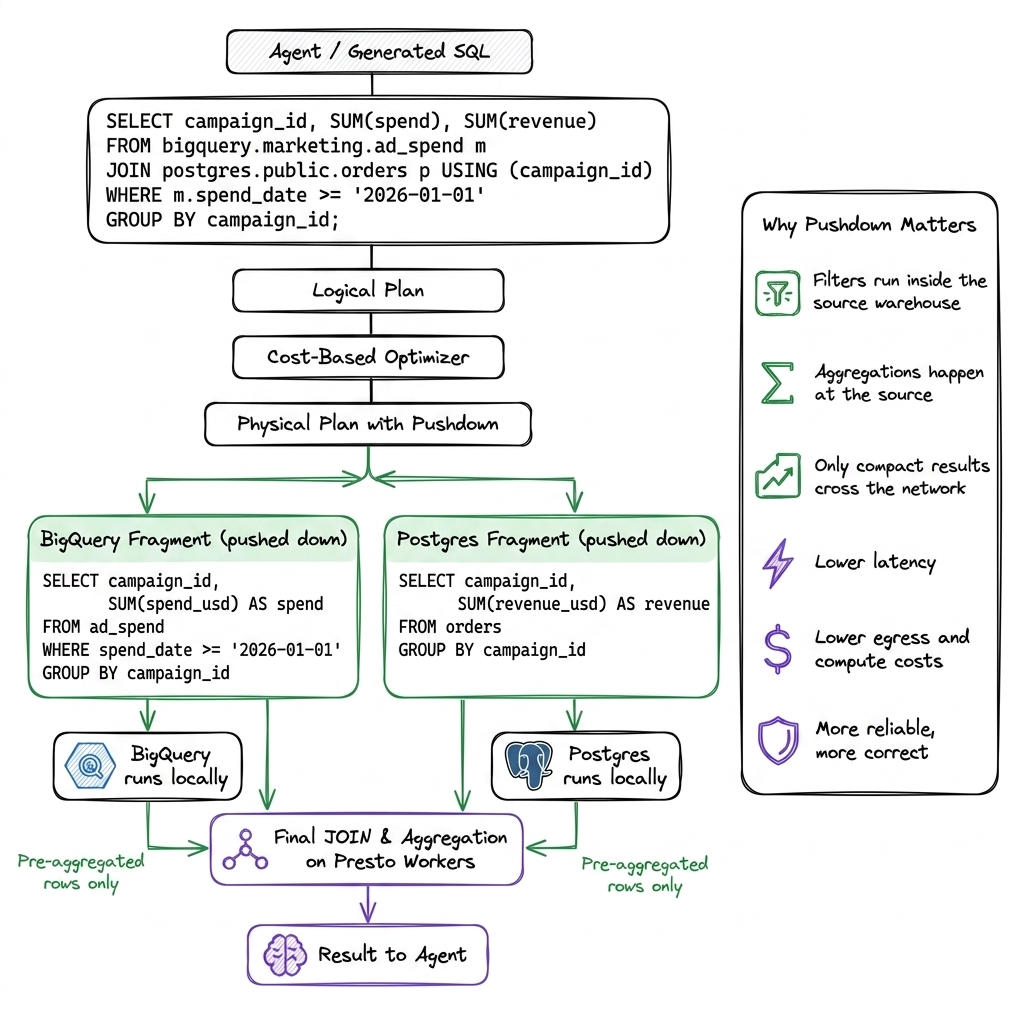
Constraint 1: Computational Pushdown
- Execution of filters occurs directly at the data source.
- Execution of aggregations occurs in its original place to minimize systemic overhead.
- Transmission is limited to highly reduced datasets across the network.
Constraint 2: Deterministic Query Optimization
- A cost-based optimizer (CBO) autonomously rewrites execution plans.
- Join reordering ensures maximum structural efficiency.
- Syntactic imperfections in agent-generated SQL are corrected automatically.
This eliminates the systemic friction of prompt-level workarounds.
Strategic Outcomes: The Operational Impact
The integration of a federated layer transcends the mere technical enablement of joins.
This architectural shift fundamentally redefines the system’s behavioral capabilities:
- Elevation of cross-source queries to first-class operations.
- Maintenance of predictable latency thresholds.
- Significant reduction in token saturation and overhead.
Ensuring deterministic correctness and analytical transparency.
The Paradigm Shift
Sylus operates beyond the constraints of a static dashboard. It functions as an autonomous system designed to:
- Execute deep data exploration.
- Synthesize high-fidelity queries.
- Maintain rapid iterative cycles.
This operational excellence is contingent upon an execution environment that is:
- Performant and low-latency.
- Reliable in its analytical output.
- Scalable across production-grade datasets.