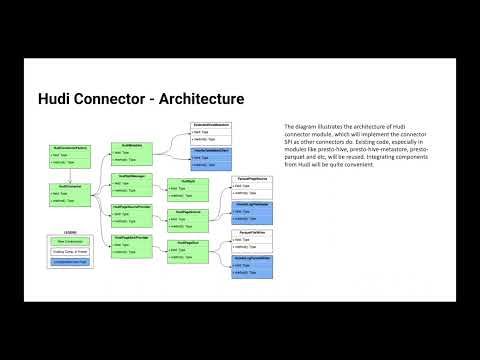
Vladimir Rodionov, founder of Carrot Cache will present the Velociraptor – the next evolution of PrestoDB hierarchical caching framework RaptorX. Velociraptor enables efficient data and meta-data caching well beyond RaptorX limits in terms of number of data files (multi-billions), number of table partitions (multi-millions) and number of table columns (multi-thousands). Velociraptor replaces all five RaptorX caches (Hive meta-data, file list, query result fragments, ORC/Parquet meta-data and data I/O) with a scalable solution, based on Carrot Cache, which does not pollute JVM heap memory, does not affect Java Garbage Collector, keeps all data and meta-data off Java heap memory or on disk and can scale well beyond server’s physical RAM limit. Velociraptor supports server restart, by quickly saving and loading data to/from disk for automatic cache warm up.