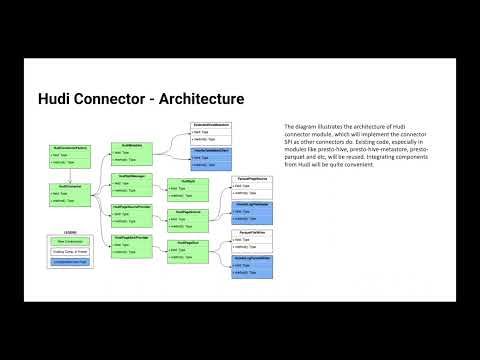
Diving into the Native Hudi connector for Presto (March 22, 2023)

In this session, we will dive deeper into the Native Hudi connector, walkthrough the various checkpoints where the query execution moves from Presto to Hudi library, and then discuss new features that are currently being developed.