TPC-H vs TPC-DS : Benchmarking Modern Distributed SQL Engines like Presto
In the world of big data, performance is the ultimate currency. But when you are processing petabytes of data across a distributed cluster, speed isn’t just about a stopwatch, it’s a high-stakes engineering challenge.
Whether you are evaluating Presto, Spark or any other engine, you need an objective yardstick. Performance in a distributed SQL engine is a multi-dimensional function of:
- I/O Throughput: How fast can data be pulled from S3 or HDFS?
- CPU Efficiency: How effectively does the engine handle serialization and compression?
- Network Latency: How much shuffling occurs between nodes?
- Optimizer Intelligence: Can the engine rewrite a query to avoid unnecessary work?
To cut through the marketing noise, the industry relies on two gold standards: TPC-H and TPC-DS.
Why Analytical Benchmarks Exist?
Before standardization, database benchmarking was dominated by vanity metrics. Vendors often cherry-picked simplistic queries to claim high performance while masking architectural weaknesses. Without a common framework for data complexity, consistency, or hardware specs, these claims lacked engineering context, making objective, apples-to-apples comparisons impossible for data architects.
Workload Classification: OLTP vs. OLAP
To understand Presto’s architecture, we must distinguish between the two primary data access patterns.
- OLTP (Online Transaction Processing): Characterized by high concurrency, point lookups (Index Scans), and small write transactions (ACID compliance). Example: Postgres serving an API.
- OLAP (Online Analytical Processing): Characterized by scanning massive datasets, columnar reads, and complex aggregations. Example: Presto generating a quarterly report.
Presto is an analytical SQL engine optimized for OLAP-style workloads such as large scans, joins, and aggregations, rather than transactional OLTP operations.
Why Query Engines Are Benchmarked?
Unlike a transactional database, an analytical engine is benchmarked on intelligence. How well can it scan billions of rows? How efficiently can it join 10 tables? Benchmarks like TPC-H and TPC-DS are designed specifically to stress-test these analytical capabilities.
The TPC: Establishing the Industry’s Standard Ruler
Founded in 1988, the Transaction Processing Performance Council (TPC) is the non-profit authority that moved the industry away from marketing claims toward verified engineering. By defining rigorous, open-source standards, the TPC provided the data ecosystem with its first “Standard Ruler”, enabling architects to make data-driven decisions based on transparent, audited performance data rather than vendor speculation.

Benchmarks solve this by replacing ad-hoc testing with a scientifically reproducible process:
- Fixed Schemas: Everyone uses the exact same table structures.
- Deterministic Data: Standardization of data generation ensures the 1TB dataset is statistically identical for everyone.
- Auditable Queries: Queries are fixed at the SQL level, while execution strategies may vary within the benchmark’s compliance rules.
TPC-H Explained
TPC-H is a standardized decision-support benchmark for analytical SQL engines. It provides a fixed data schema and 22 complex queries designed to measure how efficiently a system handles large-scale data processing under real-world business constraints.
How it Works?
Without a benchmark, fast is a subjective term. TPC-H levels the playing field by standardizing:
- The Data Model: A normalized schema reflecting a wholesale supplier.
- Data Generation: Using
dbgento ensure data distribution is identical across all tested systems. - Query Set: 22 hand-crafted SQL queries ranging from simple filters to complex multi-way joins.
- Metrics: Standardized reporting for Power (how fast) and Throughput (how many).
The Business Scenario: Wholesale Supplier Operations
TPC-H models a wholesale supplier managing orders and parts. The fictional business scenario includes:
- Suppliers providing parts to customers
- Customers placing orders for parts
- Orders consisting of line items (individual part quantities)
- Parts sourced from specific suppliers at negotiated prices
This scenario reflects traditional supply chain and order management systems, providing a realistic context for analytical queries about sales, inventory, supplier performance, and customer behavior.
TPC-H Schema Design: Normalized Relational Model
TPC-H uses a highly normalized 3NF relational schema, this model tests an engine’s ability to handle heavy joins and complex relationships.
| Table | Scale Factor (SF1000) | Role |
|---|---|---|
lineitem | ~6 Billion Rows | The “fact” table; contains every item in every order. |
orders | ~1.5 Billion Rows | Order headers, dates, and priorities. |
partsupp | ~800 Million Rows | Relationship between parts and their suppliers. |
part / customer | ~200M / ~150M | Dimensional data for filtering by segment or type. |
supplier | ~10 Million Rows | Supplier details and account balances. |
nation / region | 25 / 5 Rows | Static lookup tables for geographic analysis. |
Scale Factor (SF): SF1 = 1GB of raw data. This helps in visualizing the scale. Most modern engines (Presto, Spark, etc) benchmark at SF100 (100 GB), SF1000 (1TB), SF10000 (10TB), or higher.
What the 22 queries test?
They’re designed to force different skills in a query engine:
- Big scans + filters + group by (can you stream and aggregate efficiently?)
- Multi-way joins (can you reorder joins and choose good join algorithms?)
- Skew and selectivity (do you handle rare filters vs common filters?)
- Sorting / top-N (do you spill? do you use partial top-N?)
- Subqueries / correlated logic (optimizer maturity)
TPC-DS Explained
TPC-DS (Transaction Processing Performance Council – Decision Support) is the industry standard benchmark for measuring the performance of decision support systems (like SQL engines, Data Warehouses, and Big Data platforms). It is intentionally designed to introduce complexity, skew, and optimizer stress conditions commonly seen in production analytics. It forces the engine to solve messy, real-world problems.
How it Works?
TPC-DS tests the sophistication of the query engine. It simulates a decision support system by standardizing:
- The Data Model: A multi-dimensional Snowflake Schema representing an omnichannel retailer (Store, Web, and Catalog sales).
- Data Generation: Using
dsdgento produce datasets with significant Data Skew and non-uniform distributions, creating hot spots that punish naive execution plans. - Query Set: 99 complex SQL queries (with variations totaling ~100+) using advanced SQL features like GROUPING SETS , ROLLUP , INTERSECT, and extensive Window Functions.
- Metrics: A rigorous score combining Query Response Time (Power), Multi-user Performance (Throughput), and Data Maintenance time.
The Business Scenario: Global Retail Enterprise
TPC-DS models a large retail store chain with multiple sales channels and complex business operations. This scenario was chosen because it represents the complexity of modern retail analytics and decision support systems. The scenario includes:
- Multiple sales channels (store, catalog, web)
- Product catalog with hierarchical categorization
- Customer demographics and purchasing behavior
- Promotions and marketing campaigns
- Inventory management across warehouses
- Returns and refunds
TPC-DS Schema Design: Snowflake Schema (or Constellation Schema)
TPC-DS uses a snowflake schema with 24 tables. This is significantly more complex than TPC-H’s highly normalized 3NF schema.
Fact Tables (7):
| Category | Table Name | Business Context & Primary Data |
|---|---|---|
| Store | store_sales | Physical store transactions; measures quantity, price, and net profit. |
store_returns | In-store product returns; tracks refund amounts and processing fees. | |
| Web | web_sales | Online orders; measures shipping costs, sales price, and order numbers. |
web_returns | Web-originated returns; tracks lost revenue and account credits. | |
| Catalog | catalog_sales | Phone/mail orders; measures wholesale cost, markups, and coupons. |
catalog_returns | Catalog-based returns; tracks return taxes and refunded amounts. | |
| Inventory | inventory | Stock snapshots; measures quantity on hand per item and warehouse. |
Dimension Tables (17):
| Category | Table Name | Business Context & Primary Data |
|---|---|---|
| Customer | customer | The master identity record containing unique buyer IDs and basic info. |
customer_address | Geographical location data used for shipping, tax, and regional reporting. | |
customer_demographics | Profile attributes like gender, marital status, and education level. | |
household_demographics | Domestic context including number of dependents and vehicle ownership. | |
income_band | Specific annual income ranges to categorize purchasing power. | |
| Product | item | The product master tracking descriptions, brands, sizes, and prices. |
catalog_page | The catalog page (layout + context) that influenced a sale. | |
promotion | Marketing event details, discount types, and campaign durations. | |
| Logistics | warehouse | Storage facility metadata, including location and square footage. |
ship_mode | Shipping logistics methods like Air, Express, or Ground. | |
| Time | date_dim | Rich calendar data mapping dates to holidays, seasons, and fiscal years. |
time_dim | Clock-level breakdown of hours, minutes, and AM/PM indicators. | |
| Channels | store | Physical store location details, manager names, and operating hours. |
call_center | Attributes of phone/catalog sales centers and their tax jurisdictions. | |
web_site | Global configuration and metadata for the online sales platform. | |
web_page | Characteristics of specific URLs where web sales are triggered. | |
| Feedback | reason | Standardized descriptive codes explaining the “Why” behind returns. |
This schema complexity is what makes TPC-DS significantly harder for optimizers than TPC-H
What the 99 queries test?
The 99 TPC-DS queries are organized into categories that test different aspects of database performance and SQL capabilities.
- Iterative Reporting (The Daily Dashboard)
- What it is: Queries that compute periodic reports (e.g., Weekly Sales by State).
- What it tests: Ability to scan large amounts of data quickly and perform standard aggregations (SUM, AVG, GROUP BY).
- Data Mining (The Deep Dive)
- What it is: Queries that look for hidden patterns or trends (e.g., Find items that are bought together).
- What it tests: Complex statistical functions, self-joins (joining a table to itself), and multiple sub-queries.
- Ad-Hoc Analytics (The Random Question)
- What it is: Unpredictable questions to answer immediate business needs.
- What it tests: The Cost-Based Optimizer (CBO). Since these queries are not pre-tuned, the engine must guess the best way to execute them on the fly.
- Technical Complexity: Beyond the business content, the SQL logic itself is designed to break weak engines using:
- Common Table Expressions (CTEs): Using
WITHclauses to define temporary tables. - Window Functions: Advanced math like
RANK(),LEAD(),LAG(), andPARTITION BY - Set Operations: Using
UNION,INTERSECT, andEXCEPT. - Large Joins: Joining 10+ tables in a single query.
Query Complexity Levels:
- Simple (Queries 1-30): Basic aggregations, 1-3 table joins
- Medium (Queries 31-60): 4-7 table joins, subqueries, window functions
- Complex (Queries 61-99): 8+ table joins, nested subqueries, advanced analytics
Presto has built-in
tpchandtpcdsconnector that generates data on the fly. To enable the connector, just add a catalogtpch.propertiesandtpcds.propertiesrespectively. Unlike other engines where you must generate files (CSV/Parquet) and load them into a database. Presto’stpch,tpcdsconnectors are zero-storage and can be used for testing and education purposes only.
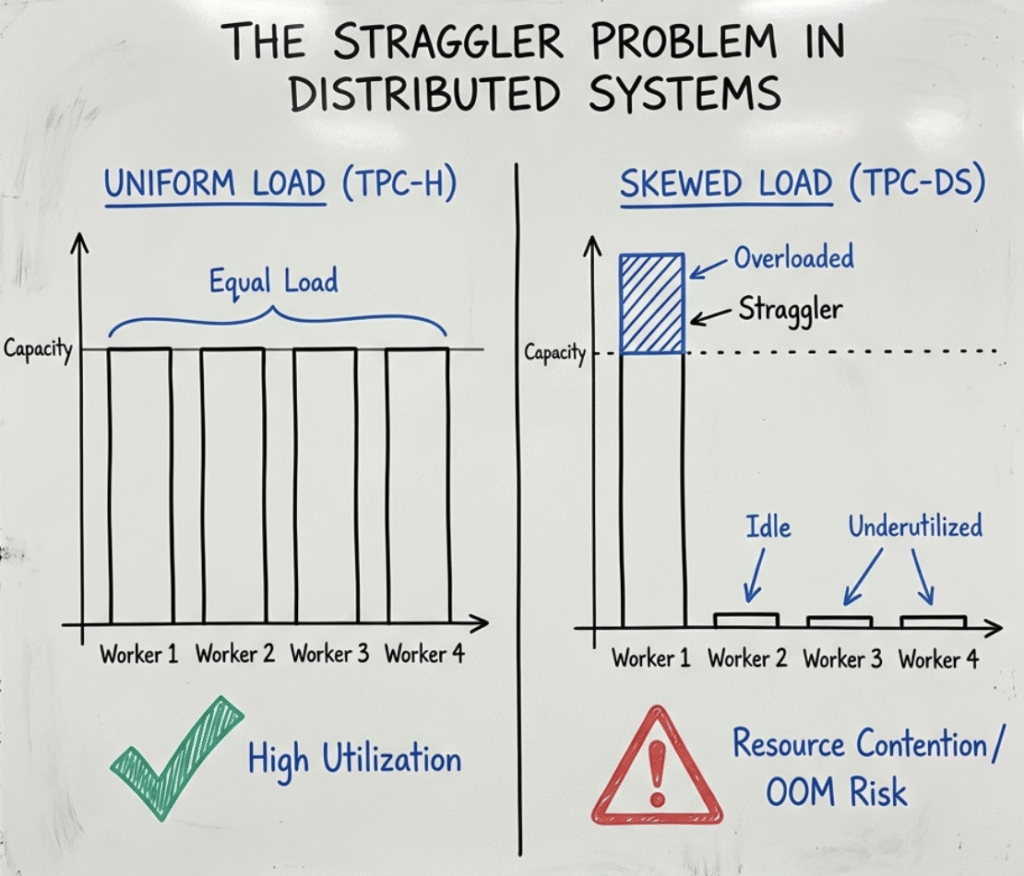
Data Skew in TPC-DS : The Critical Differentiator
A defining characteristic of TPC-DS, distinguishing it from its predecessor TPC-H, is the presence of significant Data Skew.
- TPC-H (Uniform Distribution): The TPC-H dataset generation follows a uniform probability distribution. Every partition key possesses roughly equal cardinality. While valid for baseline throughput testing, this vastly simplifies the resource management challenge by creating an artificially balanced cluster load.
- TPC-DS (Real-World Skew): TPC-DS models real-world retail phenomena using non-uniform, domain-specific statistical distributions that create realistic data skew. Certain items, dates, or customer IDs appear with orders of magnitude higher frequency than others, mimicking best-sellers or seasonal variations.
Breaking the Java Barrier: Why Presto C++ is the Future of TPC-H and TPC-DS Benchmarking
When analyzing TPC-H and TPC-DS benchmark results, it often hit a performance ceiling that isn’t caused by poor SQL, it’s caused by the Java Virtual Machine (JVM). To reach the next frontier of data lakehouse performance, the Presto community has turned to Presto C++ (powered by Velox).
If you are looking to scale your infrastructure while slashing cloud costs, here is why a native C++ worker is the single biggest architectural upgrade for your Presto cluster.
- 1. Drastic Reduction in CPU Overhead
- 2. Relieving Memory Pressure with Fine-Grained Control
- 3. Eliminating the Hidden Tax of Garbage Collection (GC)
Learn more about the Presto C++ native execution engine.
Comparison at a Glance
| Feature | TPC-H | TPC-DS |
|---|---|---|
| Model | Supply Chain (Parts & Orders) | Retail (Stores, Web, Catalog) |
| Schema | 3NF Normalized (8 Tables) | Constellation / Snowflake (24+ Tables) |
| Query Count | 22 | 99 |
| Primary Test | Join Efficiency & Raw Scan Speed | Optimizer Intelligence & Skew Handling |
| Use Case | System validation, regression testing. | Production readiness, optimizer tuning. |
Refer to Presto Documentation on TPC-H and TPC-DS for more information.