
Building Large-scale Query Operators and Window Functions for Prestissimo using Velox – Aditi Pandit

In this talk, Aditi Pandit, Principal Software Engineer at Ahana and Presto/Velox contributor, will throw the covers back on some of the most interesting portions of working in Prestissimo and Velox. The talk will be based on the experience of implementing the windowing functions in Velox. It will cover the nitty gritty on the vectorized operator, memory management and spilling. This talk is perfect for anyone who is using Presto in production and wants to understand more about the internals, or someone who is new to Presto and is looking for a deep technical understanding of the architecture.
Predicting Resource Usages of Future Queries Based on 10M Presto Queries at Twitter

Here, Chunxu and Beinan would like to share what they have learned in developing a highly-scalable query predictor service through applying machine learning algorithms to ~10 million historical Presto queries to classify queries based on their CPU times and peak memory bytes. At Twitter, this service is helping to improve the performance of Presto clusters and provide expected execution statistics on Business Intelligence dashboards.
Update on Intel’s Participation in the Presto and Velox Communities – David Cohen, Intel

In this talk I will provide a brief update on Intel’s involvement in the Presto and Velox projects.
PrestoDB, the Velox Library, and the Coming Age of Heterogeneous Hardware – Dave Cohen, Intel

This talk will quickly review the market shift to use heterogeneous hardware, the need for new language runtime and library level abstractions to hide the complexity of this hardware, and position the PrestoDB SQL query engine with the Velox and Cachelib libraries embodiments of these abstractions.
Prestissimo – Presto-on-Velox for Faster More Efficient Queries – Orri Erling, Meta

We built a drop-in replacement for the Presto worker using C++ and Velox and saw a dramatic improvements in CPU efficiency and latency for interactive queries. We embraced adaptive execution provided by Velox to efficiently evaluate filters pushed down into scan and automatically enable array-based aggregations and joins. We make extensive use of dictionary encodings to achieve zero-copy execution throughout the engine. We allow for vectorization friendly function implementations, provide ASCII-only fast paths and many other tricks. We’d like to share our learnings, early results and future plans. We are looking forward to invite the community to join our efforts in building the next generation of Presto together.
A Tour of Presto Iceberg Connector – Beinan Wang, Alluxio & Chunxu Tang, Twitter

Apache Iceberg is an open table format for huge analytic datasets. The Presto Iceberg connector consolidates the SQL engine and the table format, to empower high-performant data analytics. Here, Beinan and Chunxu would like to discuss and share the architectural design of the Presto Iceberg connector, advanced Iceberg feature support (such as native iceberg connector, row-level deletion, and iceberg v2 support), and the future roadmap.
Presto and Apache Iceberg – Chunxu Tang, Twitter

Apache Iceberg is an open table format for huge analytic datasets. At Twitter, engineers are working on the Presto-Iceberg connector, aiming to bring high-performance data analytics on Iceberg to the Presto ecosystem. Here, Chunxu would like to share what they have learned during the development, hoping to shed light on the future work of interactive queries.
Level 101 for Presto: What is PrestoDB?

In Level 101, you’ll get an overview of Presto, including: A high level overview of Presto & most common use cases The problems it solves and why you should use it A live, hands-on demo on getting Presto running on Docker Real world example: How Twitter uses Presto at scale
Level 102 for Presto: Getting Started with PrestoDB

In this tech talk, we’ll build on what we learned in Level 101 and show you how easy it is to get started with PrestoDB. We’ll also dive deeper into key features and connectors.
Level 103 for Presto: Deep Dive into the PrestoDB architecture at Twitter
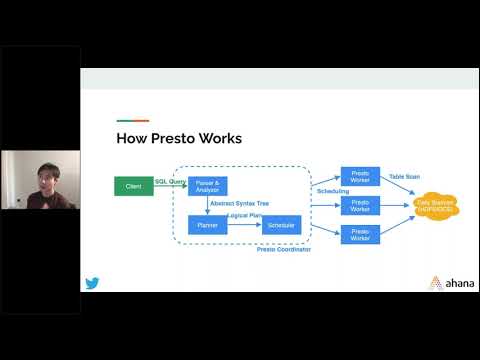
In this tech talk, we’ll take a look at the PrestoDB architecture in more technical depth. Next, we’ll have the Presto engineers at Twitter share their PrestoDB use case and architecture which includes several large Presto clusters with over 2,000 nodes.