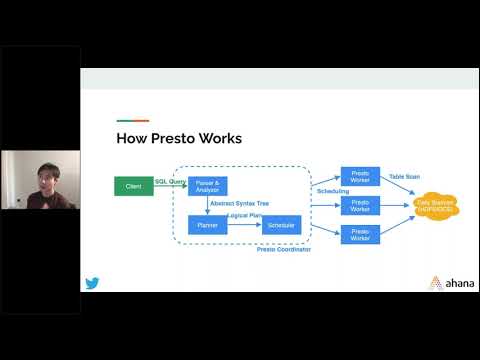
Presto on AWS Journey at Twilio – Lesson Learned and Optimization – Aakash Pradeep & Badri Tripathy

Twilio as a leader in cloud communication platforms is very heavy on data and data-based decision making. Most data related use cases are currently powered by the Presto engine. Two years back we started the Journey with Presto in Twilio and today the system has scaled to a multi-PB data lakehouse and supports more than 75k queries per day. In this journey, we learned a lot about how to effectively operationalize Presto on AWS and some of the tricks to have better query reliability, query performance, guard-railing the clusters and save cost. With this talk, we want to share this experience with the community.