
Predicting Resource Usages of Future Queries Based on 10M Presto Queries at Twitter

Here, Chunxu and Beinan would like to share what they have learned in developing a highly-scalable query predictor service through applying machine learning algorithms to ~10 million historical Presto queries to classify queries based on their CPU times and peak memory bytes. At Twitter, this service is helping to improve the performance of Presto clusters and provide expected execution statistics on Business Intelligence dashboards.
How Jampp architected a real time bidding system on AWS with PrestoDB

In this presentation, Dante and Fede will show Jampp’s data architecture, how they’re training their machine learning algorithms directly from Presto to identify potential purchasers, and why Presto has become 24/7 critical to ensure ads are relevant to users.
Presto for Real Time Analytics at Uber – Ankit Sultana, Uber

The Real Time Analytics Platform at Uber serves 100M+ queries daily and is used for several critical features: from end-user app features to radius selection for Uber Eats. All these queries are proxied via a custom internal fork of Presto (named Neutrino) that is optimized for low-latency/high-throughput (50ms latency at 1000s of RPS). With this talk we plan to share our learnings over the last 6 months and how we run Presto reliably at this scale for real-time analytics.
A Tour of Presto Iceberg Connector – Beinan Wang, Alluxio & Chunxu Tang, Twitter

Apache Iceberg is an open table format for huge analytic datasets. The Presto Iceberg connector consolidates the SQL engine and the table format, to empower high-performant data analytics. Here, Beinan and Chunxu would like to discuss and share the architectural design of the Presto Iceberg connector, advanced Iceberg feature support (such as native iceberg connector, row-level deletion, and iceberg v2 support), and the future roadmap.
Realtime Analytics with Presto and Apache Pinot – Xiang Fu

In this world, most analytics products either focus on ad-hoc analytics, which requires query flexibility without guaranteed latency, or low latency analytics with limited query capability. In this talk, we will explore how to get the best of both worlds using Apache Pinot and Presto: 1. How people do analytics today to trade-off Latency and Flexibility: Comparison over analytics on raw data vs pre-join/pre-cube dataset. 2. Introduce Apache Pinot as a column store for fast real-time data analytics and Presto Pinot Connector to cover the entire landscape. 3. Deep dive into Presto Pinot Connector to see how the connector does predicate and aggregation push down. 4. Benchmark results for Presto Pinot connector.
Presto and Apache Iceberg – Chunxu Tang, Twitter

Apache Iceberg is an open table format for huge analytic datasets. At Twitter, engineers are working on the Presto-Iceberg connector, aiming to bring high-performance data analytics on Iceberg to the Presto ecosystem. Here, Chunxu would like to share what they have learned during the development, hoping to shed light on the future work of interactive queries.
Level 101 for Presto: What is PrestoDB?

In Level 101, you’ll get an overview of Presto, including: A high level overview of Presto & most common use cases The problems it solves and why you should use it A live, hands-on demo on getting Presto running on Docker Real world example: How Twitter uses Presto at scale
Level 102 for Presto: Getting Started with PrestoDB

In this tech talk, we’ll build on what we learned in Level 101 and show you how easy it is to get started with PrestoDB. We’ll also dive deeper into key features and connectors.
Level 103 for Presto: Deep Dive into the PrestoDB architecture at Twitter
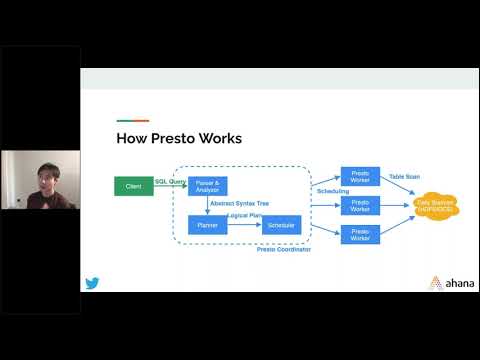
In this tech talk, we’ll take a look at the PrestoDB architecture in more technical depth. Next, we’ll have the Presto engineers at Twitter share their PrestoDB use case and architecture which includes several large Presto clusters with over 2,000 nodes.