Quick Stats – Runtime ANALYZE for Better Query Plans – Anant Aneja, Ahana

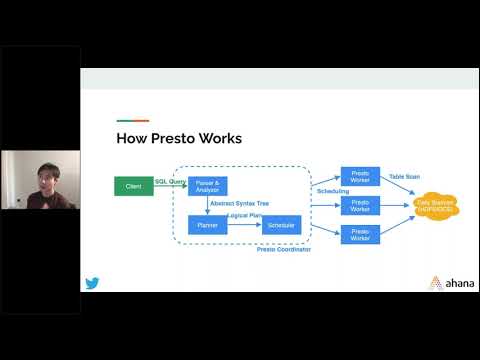
An optimizer’s plans are only as good as the estimates available for the tables its querying. For queries over recently ingested data that is not yet ANALYZE-d to update table or partition stats, the Presto optimizer flies blind; it is unable to make good query plans and resorts to syntactic join orders. To solve this problem, we propose building ‘Quick Stats’ : By utilizing file level metadata available in open data lake formats such as Delta & Hudi, and by examining stats from Parquet & ORC footers, we can build a representative stats sample at a per partition level. These stats can be cached for use be newer queries, and can also be persisted back to the metastore. New strategies for tuning these stats, such as sampling, can be added to improve their precision.