Keynote Panel: Presto at Scale – Shradha Ambekar, Gurmeet Singh, Neerad Somanchi & Rupa Gangatirkar

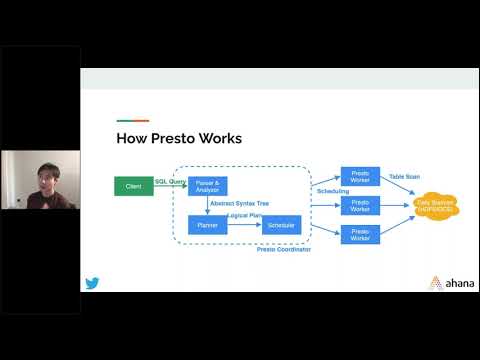
Over the last decade Presto has become one of the most widely adopted open source SQL query engines. In use at companies large and small, Presto’s performance, reliability, and efficiency at scale have become critical to many companies’ data infrastructures. In this panel we’ll hear from three of the largest companies running Presto at scale – Meta, Uber, and Intuit. They’ll share more about their learnings, some of their impressive performance metrics with Presto, and what they envision going forward for Presto at their respective companies.