Predicting Resource Usages of Future Queries Based on 10M Presto Queries at Twitter

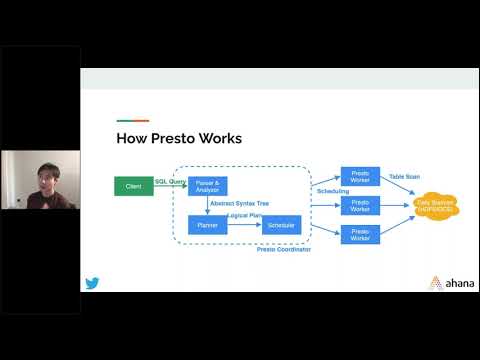
Here, Chunxu and Beinan would like to share what they have learned in developing a highly-scalable query predictor service through applying machine learning algorithms to ~10 million historical Presto queries to classify queries based on their CPU times and peak memory bytes. At Twitter, this service is helping to improve the performance of Presto clusters and provide expected execution statistics on Business Intelligence dashboards.