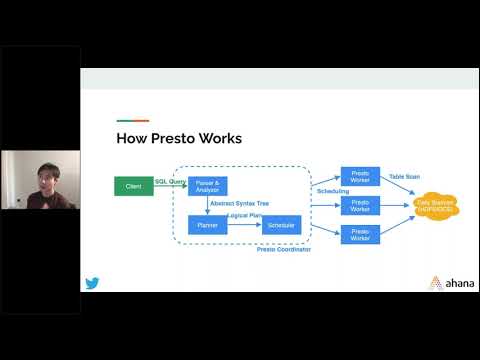
Implementing Lakehouse Architecture with Presto at Bolt – Kostiantyn Tsykulenko, Bolt.eu

Bolt.eu is the first European mobility super-app. We have over 100M users across Europe and Africa and have to deal with data at a large scale on a daily basis (over 100k queries daily). Previously we were using a traditional data warehouse solution based on Redshift but we’ve faced scalability issues that were hard to overcome and after doing our research we chose Presto as the solution. In just a single year we’ve managed to migrate to the Lakehouse architecture using AWS, Presto, Spark and Delta lake. We would like to talk about our journey, some of the challenges we’ve encountered and how we solved them.