Building Modern Data Lakes for Analytics Using Object Storage – Satish Ramakrishnan, MinIO

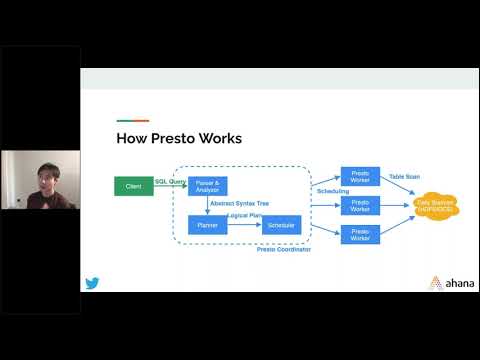
The modern data lake is distributed, unstructured and demands performance and scale – or better stated, performance at scale. Modern object stores are the ideal platform to pair with MPP query engines like Presto – particularly as the scale reaches tens or hundreds of petabytes with tens to hundreds of concurrent queries. In this talk, Satish Ramakrishnan will outline the better together attributes of the two technologies with a focus on the most sophisticated modern object storage features – from throughput optimizations, multi-cloud capabilities, cross-cloud active active replication and lifecycle management. Participants will come away with a reference architecture suited to query processing at object scale.