Apache Hudi for Presto and how it’s used at Bytedance
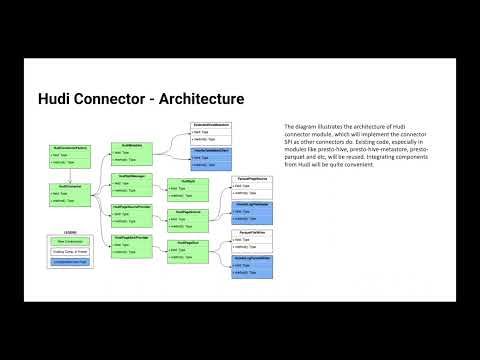
This month we’ll have Yanbing Zhang, software engineer at Bytedance, share more about their work on the Apache Hudi Connector for Presto and how they’re using it at Bytedance.
On-Demand Recordings from PrestoCon’s, Webinars, Meetups, and more
This month we’ll have Yanbing Zhang, software engineer at Bytedance, share more about their work on the Apache Hudi Connector for Presto and how they’re using it at Bytedance.

Vladimir Rodionov, founder of Carrot Cache will present the Velociraptor – the next evolution of PrestoDB hierarchical caching framework RaptorX. Velociraptor enables efficient data and meta-data caching well beyond RaptorX limits in terms of number of data files (multi-billions), number of table partitions (multi-millions) and number of table columns (multi-thousands). Velociraptor replaces all five RaptorX caches (Hive meta-data, file list, query result fragments, ORC/Parquet meta-data and data I/O) with a scalable solution, based on Carrot Cache, which does not pollute JVM heap memory, does not affect Java Garbage Collector, keeps all data and meta-data off Java heap memory or on disk and can scale well beyond server’s physical RAM limit. Velociraptor supports server restart, by quickly saving and loading data to/from disk for automatic cache warm up.

Shengxuan Liu from ByteDance and Beinan Wang from Alluxio will present the practical problems and interesting findings during the launch of Presto Router and Alluxio Local Cache. Their talk covers how ByteDance’s Presto team implements the cache invalidation and dashboard for Alluxio’s Local Cache. Shengxuan will also share his experience using a customized cache strategy to improve the cache efficiency and system reliability.

Presto has been widely used at Bytedance in several ways such as in the data warehouse, BI tools, ads etc. And, the Presto team at Bytedance has also delivered many key features and optimizations such as the Hive UDF wrapper, coordinator, runtime filter and so on which extend Presto usages and enhance Presto stabilities. Nowadays, most companies will use both Hive (or Spark) and Presto together. But Presto UDFs have very different syntax and internal mechanisms compared with Hive UDFs. This restricts Presto usage while users need to maintain 2 kinds of functions. In this talk, we will present a way to execute Hive UDF/UDAF inside Presto.

Presto supports dynamically registered User Defined Functions (UDFs) since 2020. Over the years, we used this framework to add support for SQL UDFs and remote / external UDFs. One common community request in the UDF domain is to support Hive UDFs. Many companies have legacy Hive pipelines, and engineers who are familiar with HQL and Hive UDFs. With remote UDF, one can implement Hive UDF support as UDFs running on the remote cluster. But since HiveUDFs are written in Java, we can also run them inside the engine. We extended the dynamic UDF framework to support Java UDFs, and used this new extension to add HiveUDF support in Presto. With this feature, users can directly use their familiar HiveUDFs and UDAFs in their Presto query.

Presto has been widely used in Bytedance, e.g. DataWarehouse, BI Tools, Ads and so on. Meanwhile the presto team of Bytedance also delivered many important features and optimizations like Hive UDF Wrapper, multiple coordinator, runtime filter and so on which extend Presto usages and enhance Presto stababilities.

Presto has been widely used at Bytedance in several ways such as in the data warehouse, BI tools, ads etc. And, the Presto team at Bytedance has also delivered many key features and optimizations such as the Hive UDF wrapper, coordinator, runtime filter and so on which extend Presto usages and enhance Presto stabilities. Nowadays, most companies will use both Hive (or Spark) and Presto together. But Presto UDFs have very different syntax and internal mechanisms compared with Hive UDFs. This restricts Presto usage while users need to maintain 2 kinds of functions. In this talk, we will present a way to execute Hive UDF/UDAF inside Presto.