Apache Hudi for Presto and how it’s used at Bytedance
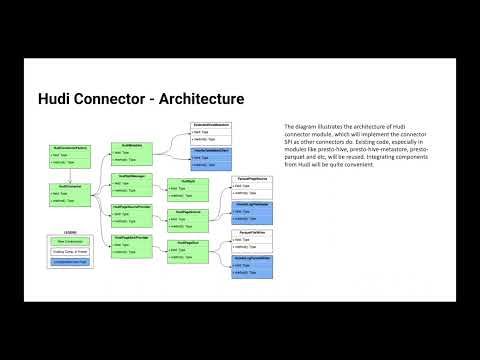
This month we’ll have Yanbing Zhang, software engineer at Bytedance, share more about their work on the Apache Hudi Connector for Presto and how they’re using it at Bytedance.
On-Demand Recordings from PrestoCon’s, Webinars, Meetups, and more
This month we’ll have Yanbing Zhang, software engineer at Bytedance, share more about their work on the Apache Hudi Connector for Presto and how they’re using it at Bytedance.

Rajmani Arya, Varun Senthilnathan & Manoj Kumar Dhakad, Adobe Advertising: We are from the Product Engineering team in Adobe Advertising (https://business.adobe.com/in/product…. Adobe Advertising is a digital advertisement platform. We take care of accumulating all data, providing platform intelligence, building and maintaining machine leaning capabilities, building and maintaining internal pipelines that form derived data to be used by other teams. The volume of total incoming raw data ranges between 8 to 10 tb/ day spread across 7 regions. The total data in the system currently is about 7pb. This data is largely stored in Hive tables with a central metastore. We use Presto in three ways: 1. Data studio – an internal tool to enable data analysts, sales, marketing and other teams to do adhoc querying. This is also used by data engineers to do adhoc querying for engineering tasks. 2. Custom Reports – We create reports for customers to get performance insights on their campaigns. We have 100s of reports that are run on a daily basis. 3. Internal Pipelines – Presto is used to retrieve data to power 100s of pipelines run daily to generate derived data.

Shengxuan Liu from ByteDance and Beinan Wang from Alluxio will present the practical problems and interesting findings during the launch of Presto Router and Alluxio Local Cache. Their talk covers how ByteDance’s Presto team implements the cache invalidation and dashboard for Alluxio’s Local Cache. Shengxuan will also share his experience using a customized cache strategy to improve the cache efficiency and system reliability.

Ending DAG Distress: Building Self-Orchestrating Pipelines for Presto – Roy Hasson, Upsolver dbt and Airflow is a popular combination for creating and scheduling batch data modeling and transformation jobs that execute in a data warehouse like Snowflake. Presto users querying the data lake need a similar solution that is simple to use and makes it easy to ingest, model, transform and maintain datasets, without having to write or manage complex DAGs. In this session you will learn how Upsolver built a tool that allows engineers, developers and analysts to write data pipelines using SQL. Pipelines are automatically orchestrated, are data-aware and maintain a consistent data contract between each stage of the pipeline. You will also learn how to introduce the idea of data products into your company to enable more self-service for your Presto users.

Presto has been widely used at Bytedance in several ways such as in the data warehouse, BI tools, ads etc. And, the Presto team at Bytedance has also delivered many key features and optimizations such as the Hive UDF wrapper, coordinator, runtime filter and so on which extend Presto usages and enhance Presto stabilities. Nowadays, most companies will use both Hive (or Spark) and Presto together. But Presto UDFs have very different syntax and internal mechanisms compared with Hive UDFs. This restricts Presto usage while users need to maintain 2 kinds of functions. In this talk, we will present a way to execute Hive UDF/UDAF inside Presto.

Presto supports dynamically registered User Defined Functions (UDFs) since 2020. Over the years, we used this framework to add support for SQL UDFs and remote / external UDFs. One common community request in the UDF domain is to support Hive UDFs. Many companies have legacy Hive pipelines, and engineers who are familiar with HQL and Hive UDFs. With remote UDF, one can implement Hive UDF support as UDFs running on the remote cluster. But since HiveUDFs are written in Java, we can also run them inside the engine. We extended the dynamic UDF framework to support Java UDFs, and used this new extension to add HiveUDF support in Presto. With this feature, users can directly use their familiar HiveUDFs and UDAFs in their Presto query.

Presto has been widely used in Bytedance, e.g. DataWarehouse, BI Tools, Ads and so on. Meanwhile the presto team of Bytedance also delivered many important features and optimizations like Hive UDF Wrapper, multiple coordinator, runtime filter and so on which extend Presto usages and enhance Presto stababilities.

Presto has been widely used at Bytedance in several ways such as in the data warehouse, BI tools, ads etc. And, the Presto team at Bytedance has also delivered many key features and optimizations such as the Hive UDF wrapper, coordinator, runtime filter and so on which extend Presto usages and enhance Presto stabilities. Nowadays, most companies will use both Hive (or Spark) and Presto together. But Presto UDFs have very different syntax and internal mechanisms compared with Hive UDFs. This restricts Presto usage while users need to maintain 2 kinds of functions. In this talk, we will present a way to execute Hive UDF/UDAF inside Presto.