Apache Hudi for Presto and how it’s used at Bytedance
This month we’ll have Yanbing Zhang, software engineer at Bytedance, share more about their work on the Apache Hudi Connector for Presto and how they’re using it at Bytedance.
On-Demand Recordings from PrestoCon’s, Webinars, Meetups, and more
This month we’ll have Yanbing Zhang, software engineer at Bytedance, share more about their work on the Apache Hudi Connector for Presto and how they’re using it at Bytedance.

Over the last decade Presto has become one of the most widely adopted open source SQL query engines. In use at companies large and small, Presto’s performance, reliability, and efficiency at scale have become critical to many companies’ data infrastructures. In this panel we’ll hear from three of the largest companies running Presto at scale – Meta, Uber, and Intuit. They’ll share more about their learnings, some of their impressive performance metrics with Presto, and what they envision going forward for Presto at their respective companies.

Shengxuan Liu from ByteDance and Beinan Wang from Alluxio will present the practical problems and interesting findings during the launch of Presto Router and Alluxio Local Cache. Their talk covers how ByteDance’s Presto team implements the cache invalidation and dashboard for Alluxio’s Local Cache. Shengxuan will also share his experience using a customized cache strategy to improve the cache efficiency and system reliability.

PrestoDB recently underwent major architectural updates as the Presto Foundation grows membership and is looking to vastly grow the number of new commits and forks. Achieving this desired end state required successful refactoring and improving of Presto’s already impressive speed, efficiency, reliability, and extensibility. Establishing PrestoDB as a premier Open Source project required a major commitment of time and resources from Meta to ensure the community can benefit from this project for years to come, as well as positioning PrestoDB to evolve beyond what Meta alone could create. Members of the Presto Foundation need more of you to be involved in this major evolution in Presto’s history and core components, and bring your own inventive ideas to the mix.

Facebook operates Presto at an enormous scale. A critical part of the success of Presto is properly tuning the clusters according to the use case they target. Swapnil Tailor, Basar Onat and Tim Meehan describe important session properties and configuration properties used to configure Presto, and guidance on when and how to use them.

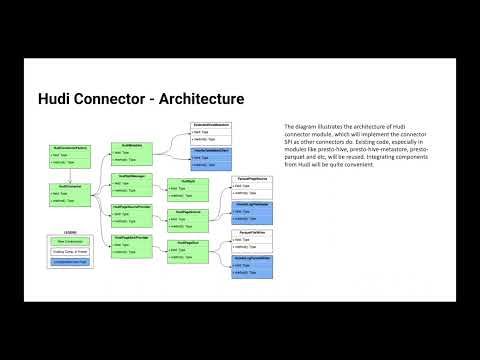
Presto has been widely used at Bytedance in several ways such as in the data warehouse, BI tools, ads etc. And, the Presto team at Bytedance has also delivered many key features and optimizations such as the Hive UDF wrapper, coordinator, runtime filter and so on which extend Presto usages and enhance Presto stabilities. Nowadays, most companies will use both Hive (or Spark) and Presto together. But Presto UDFs have very different syntax and internal mechanisms compared with Hive UDFs. This restricts Presto usage while users need to maintain 2 kinds of functions. In this talk, we will present a way to execute Hive UDF/UDAF inside Presto.

At Facebook, we have spent the past several years in independently building and scaling both Presto and Spark to Facebook scale batch workloads. It is now increasingly evident that there is significant value in coupling Presto’s state-of-art low-latency evaluation with Spark’s robust and fault tolerant execution engine. In this talk, we’ll take a deep dive in Presto and Spark architecture with a focus on key differentiators (e.g., disaggregated shuffle) that are required to further scale Presto.

In this round table moderated by Eric Kavanagh of The Bloor Group, panelists from Uber, Facebook, Ahana, and Alibaba will discuss all aspects of building a thriving open source community around PrestoDB including why Presto is so popular & the problems it solves, the open source model the foundation follows, why governance and transparency are so important to an open source community, and what the community looks for in open source projects.

In complex analytics queries, we often see repeated expressions, for example parsing the same JSON column but extracting different fields, elaborate CASE statement with common predicates and different ones. Previously, Presto will compute the same expression many times as they appear in query. With common sub expression optimization, we would only evaluate the same expression once within the same project operator or filter operator. In our workload, we’ve seen 3x improvements on certain queries with expensive common sub expressions like JSON_PARSE. Microbenchmark also shows a consistent ~10% performance improvement for simple common sub-expressions like x + y. In this talk, we will talk about how this is implemented.

The experimentation platform is one of the most important use cases supported by Presto at Meta. This talk introduces the background, requirements, architecture and how we addressed the challenge problems with Presto and shares lessons we learned from supporting this use case.

Presto supports dynamically registered User Defined Functions (UDFs) since 2020. Over the years, we used this framework to add support for SQL UDFs and remote / external UDFs. One common community request in the UDF domain is to support Hive UDFs. Many companies have legacy Hive pipelines, and engineers who are familiar with HQL and Hive UDFs. With remote UDF, one can implement Hive UDF support as UDFs running on the remote cluster. But since HiveUDFs are written in Java, we can also run them inside the engine. We extended the dynamic UDF framework to support Java UDFs, and used this new extension to add HiveUDF support in Presto. With this feature, users can directly use their familiar HiveUDFs and UDAFs in their Presto query.

Building open and shared foundational tech to build a lake house architecture can provide the best-of-breed user experience across the Analytics and ML domains and potentially beyond. In this talk, Biswa will share examples drawn from the evolution of the data stack at Meta over the last few years including efforts towards dialect unification (Sapphire aka Presto-on-Spark and Xstream-IE streaming engine efforts), eval unification (using Velox as the base), eliminating the need for data duplication for interactive analytics by building smart caching (RaptorX), building a best-of-breed file format that works across Analytics and ML (Alpha), and building an open source ML data pre-proc engine (TorchArrow) which shares the core dialect and eval components with Presto.

Today’s digital-native companies need a modern data infra that can handle data wrangling and data-driven analytics for the ever-increasing amount of data needed to drive business. Specifically, they need to address challenges like complexity, cost, and lock-in. An Open SQL Data Lakehouse approach enables flexibility and better cost performance by leveraging open technologies and formats. Join us for this panel where leading technologists from the Presto open source project will share their vision of the SQL Data Lakehouse and why Presto is a critical component.

Meta uses Presto extensively for batch. Come learn about the architecture of Meta’s batch usage, how Presto is tuned in batch clusters, how monitoring and reliability is set up, and the future direction with Spark.

Presto on Spark is an integration between Presto and Spark that leverages Presto’s compiler/evaluation as a library and Spark’s large scale processing capabilities. It enables a unified SQL experience between interactive and batch use cases. A unified option for batch data processing and ad hoc is very important for creating the experience of queries that scale instead of fail without requiring rewrites between different SQL dialects. In this session, we’ll talk about Presto On Spark architecture, why it matters and its implementation/usage at Intuit.

Presto on elastic capacity – Elasticity of a shared fleet is one of the fundamental pillars of the IaaS (Infrastructure-as-a-Service) world. The ability of services to efficiently use both guaranteed and non-guaranteed (opportunistic) capacity is important in such a setting. Presto is great when it runs on guaranteed capacity (i.e, capacity that is fixed and stable). But what if we want Presto to leverage elastic (opportunistic) capacity, i.e, capacity that is shifting, but in a predictable manner (think Amazon EC2 Spot Blocks)? In this lightning presentation, Neerad Somanchi and Abhisek Saikia will talk about how a recent feature developed for Presto can help it efficiently utilize such elastic compute.

Presto has been widely used in Bytedance, e.g. DataWarehouse, BI Tools, Ads and so on. Meanwhile the presto team of Bytedance also delivered many important features and optimizations like Hive UDF Wrapper, multiple coordinator, runtime filter and so on which extend Presto usages and enhance Presto stababilities.

We built a drop-in replacement for the Presto worker using C++ and Velox and saw a dramatic improvements in CPU efficiency and latency for interactive queries. We embraced adaptive execution provided by Velox to efficiently evaluate filters pushed down into scan and automatically enable array-based aggregations and joins. We make extensive use of dictionary encodings to achieve zero-copy execution throughout the engine. We allow for vectorization friendly function implementations, provide ASCII-only fast paths and many other tricks. We’d like to share our learnings, early results and future plans. We are looking forward to invite the community to join our efforts in building the next generation of Presto together.