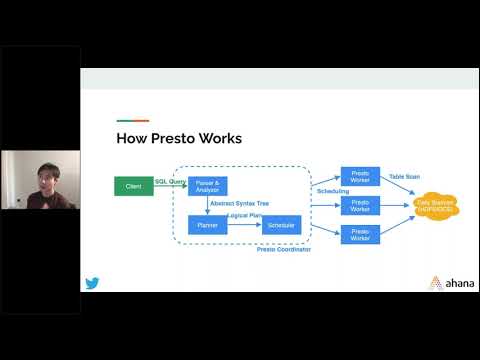
Exploring New Frontiers: How Apache Flink, Apache Hudi and Presto Power New Insights and Gold Nuggets at Scale

Danny Chan & Sagar Sumit, Onehouse – In this talk, attendees will walk away with: – The current challenges of analytics on transactional data systems with data streams at scale – How the Hudi unlocks incremental processing on the lake – How Presto allows ad-hoc queries that support data exploration on Flink data – How you can leverage Flink, Hudi and Presto to build incremental materialized views