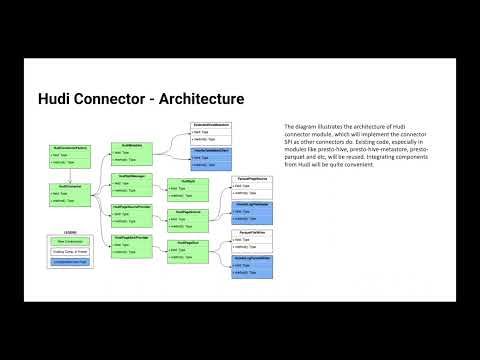
Apache Hudi is a data lake platform that supercharges data lakes. Originally created at Uber, Hudi provides various ways to strike trade-offs between ingestion speed and query performance by supporting user defined partitioners, automatic file sizing which are favorable to query performance. Hudi integrates with PrestoDB to make this data available for queries. During ingestion, data is typically co-located based on arrival time. However, query engines perform better when the data frequently queried is co-located together, which may be different from arrival time order. We will discuss a new framework called “data clustering” to make data lakes adaptable to query patterns, thereby improving query latencies. Finally, we will discuss future work to support improving data locality using custom bucketing of data during ingestion, avoiding some of the rewrite costs.