Learning & Operating Presto | Caching in Presto (Sept 28, 2023)

Dive into the new O’Reilly ebook, Learning & Operating Presto. Hear from Alluxio on different ways to get caching in Presto.
On-Demand Recordings from PrestoCon’s, Webinars, Meetups, and more
Dive into the new O’Reilly ebook, Learning & Operating Presto. Hear from Alluxio on different ways to get caching in Presto.

Learn more about the new open-source Redis-based Historical Statistics Provider for Presto from Jay Narale, software engineer at Uber who built it. Redis is an open-source in-memory database that integrates with Presto through a dedicated connector. Now with a Redis history-based optimizer, you can enhance the efficiency and speed of query execution for Presto by using historical stats to generate optimized plans for your queries. Jay will cover how the Redis HBO utilizes the in-memory capabilities of Redis to store & analyze historical query execution data, which helps the optimizer make informed decisions about query planning and resource allocation based on the historical patterns of queries, leading to improved execution times and resource utilization.

Update from Presto Technical Steering Committee Chair Tim Meehan Hear the latest from Tim Meehan, Chair of the Presto TSC. Also learn how compute.ai enables high performance SQL with Presto

In this session, we will dive deeper into the Native Hudi connector, walkthrough the various checkpoints where the query execution moves from Presto to Hudi library, and then discuss new features that are currently being developed.
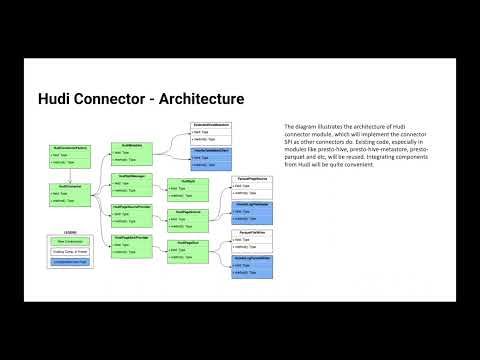
This month we’ll have Yanbing Zhang, software engineer at Bytedance, share more about their work on the Apache Hudi Connector for Presto and how they’re using it at Bytedance.

The Presto Foundation is the organization that oversees the development of the Presto open source project. Hosted at the Linux Foundation, the Presto Foundation operates under a community governance model with representation from all its members. In this fireside chat, we’ll hear more from Girish Baliga, Chair of the Presto Foundation, on what it actually means to be a Presto Foundation member and why this governance model is so important for open source projects. We’ll also talk with Vikram Murali of IBM, the newest member of the Presto Foundation. He’ll share more about IBM’s journey to Presto, how they’re using it in IBM’s new watsonx.data lakehouse, and why the Presto Foundation played an important role in IBM’s decision to choose Presto.

Vladimir Rodionov, founder of Carrot Cache will present the Velociraptor – the next evolution of PrestoDB hierarchical caching framework RaptorX. Velociraptor enables efficient data and meta-data caching well beyond RaptorX limits in terms of number of data files (multi-billions), number of table partitions (multi-millions) and number of table columns (multi-thousands). Velociraptor replaces all five RaptorX caches (Hive meta-data, file list, query result fragments, ORC/Parquet meta-data and data I/O) with a scalable solution, based on Carrot Cache, which does not pollute JVM heap memory, does not affect Java Garbage Collector, keeps all data and meta-data off Java heap memory or on disk and can scale well beyond server’s physical RAM limit. Velociraptor supports server restart, by quickly saving and loading data to/from disk for automatic cache warm up.

Varsity Tutors is a learning platform that enables online academic, professional, and enrichment learning. A growing part of their offering partners with school districts to provide customized support for teachers and students. Varsity Tutors for Schools provides external reporting capabilities including student assessments, progress reports, and more. To provide these timely reports, Varsity Tutors (an AWS shop) uses Presto scripts to perform federated queries across MySQL, Postgres, and Redshift and writes data back to S3. They use Ahana Cloud as their managed service for Presto. In this session, John will discuss what technologies they evaluated, why they chose Presto, and their current data architecture including how they handle security for cross-account writes and how they perform upserts into the final reporting database.

Biddut Sarker Bijoy will discuss his experience utilizing Presto in projects involving billions of data points. Many of the big data projects Biddut Sarker Bijoy worked on have had computational issues, such as the need to shrink datasets or the challenge of making sense of terabytes of data. Nonetheless, Biddut Sarker Bijoy recently worked on a project that required him to clean up a large database. Sometimes we all need to clean up a database. It was not a straightforward one for many reasons. Biddut Sarker Bijoy have found using Presto is the best-fitted one for this problem because of its architectural behavior and how it works with billions of data points within a very short amount of time as well as with a less amount of cost.

Over the last decade Presto has become one of the most widely adopted open source SQL query engines. In use at companies large and small, Presto’s performance, reliability, and efficiency at scale have become critical to many companies’ data infrastructures. In this panel we’ll hear from three of the largest companies running Presto at scale – Meta, Uber, and Intuit. They’ll share more about their learnings, some of their impressive performance metrics with Presto, and what they envision going forward for Presto at their respective companies.

An optimizer’s plans are only as good as the estimates available for the tables its querying. For queries over recently ingested data that is not yet ANALYZE-d to update table or partition stats, the Presto optimizer flies blind; it is unable to make good query plans and resorts to syntactic join orders. To solve this problem, we propose building ‘Quick Stats’ : By utilizing file level metadata available in open data lake formats such as Delta & Hudi, and by examining stats from Parquet & ORC footers, we can build a representative stats sample at a per partition level. These stats can be cached for use be newer queries, and can also be persisted back to the metastore. New strategies for tuning these stats, such as sampling, can be added to improve their precision.

Traditionally, the deployment of Presto has been limited to Intel processors with the x86 architecture. However, with the growing popularity of ARM architecture, Chunxu and Jiaming have extended the Presto ecosystem to ARM and conducted a series of benchmark experiments. Their objective is to evaluate the performance of Presto on ARM architecture and identify key insights from the experiments. In this presentation, Chunxu and Jiaming will share the results of their performance evaluation and discuss some of the most significant findings from their research.

HPE Ezmeral Unified Analytics is an end-to-end data & AI/ML platform that consists of several popular open-source frameworks for data engineering, data analytics, data science, & ML engineering in a well-integrated packaging. These open-source frameworks include Apache Spark, Apache Airflow, Apache Superset, PrestoDB, MLFlow, Kubeflow, and Feast. This platform is built atop Kubernetes and provides built in security. In this talk we will focus on the role of PrestoDB in Unified Analytics as a fast SQL query engine, and also as a secure data access layer. We will discuss some of our value-additions to PrestoDB, such as a distributed memory-centric columnar caching layer that provides both explicit and transparent caching for dataset fragments, often leading to 3x to 4x query performance. We will conclude by proposing to make caching pluggable in PrestoDB and discussing future directions.

Bolt.eu is the first European mobility super-app. We have over 100M users across Europe and Africa and have to deal with data at a large scale on a daily basis (over 100k queries daily). Previously we were using a traditional data warehouse solution based on Redshift but we’ve faced scalability issues that were hard to overcome and after doing our research we chose Presto as the solution. In just a single year we’ve managed to migrate to the Lakehouse architecture using AWS, Presto, Spark and Delta lake. We would like to talk about our journey, some of the challenges we’ve encountered and how we solved them.

Danny Chan & Sagar Sumit, Onehouse – In this talk, attendees will walk away with: – The current challenges of analytics on transactional data systems with data streams at scale – How the Hudi unlocks incremental processing on the lake – How Presto allows ad-hoc queries that support data exploration on Flink data – How you can leverage Flink, Hudi and Presto to build incremental materialized views


